Explore the videos: hover to play, and slide to see LQ vs HQ differences.
Abstract
Video super-resolution (VSR) aims to reconstruct a high-resolution (HR) video from a low-resolution (LR) counterpart. Achieving successful VSR requires producing realistic HR details and ensuring both spatial and temporal consistency. To restore realistic details, diffusion-based VSR approaches have recently been proposed. However, the inherent randomness of diffusion, combined with their tile-based approach, often leads to spatio-temporal inconsistencies. In this paper, we propose DC-VSR, a novel VSR approach to produce spatially and temporally consistent VSR results with realistic textures. To achieve spatial and temporal consistency, DC-VSR adopts a novel Spatial Attention Propagation (SAP) scheme and a Temporal Attention Propagation (TAP) scheme that propagate information across spatio-temporal tiles based on the self-attention mechanism. To enhance high-frequency details, we also introduce Detail-Suppression Self-Attention Guidance (DSSAG), a novel diffusion guidance scheme. Comprehensive experiments demonstrate that DC-VSR achieves spatially and temporally consistent, high-quality VSR results, outperforming previous approaches.
Method
DC-VSR enhances low-resolution videos to any high-resolution videos. To deal with any size of videos, DC-VSR processes inputs with overlapping spatio-temporal tiles. However, tile-based approach has inconsistency problem among separated tiles. By employing Spatial Attention Propagation (SAP) and Temporal Attention Propagation (TAP), the sharing of information among spatio-temporal tiles leads to spatially and temporally consistent high-resolution videos. Furthermore, to improve the video frame quality, latents in each diffusion timesteps go through Detail-Suppression Self-Attention Guidance (DSSAG). DSSAG leads model to generate fine detail and clear frames.
DC-VSR Video
DSSAG: A General Technique for Enhancing Visual Synthesis
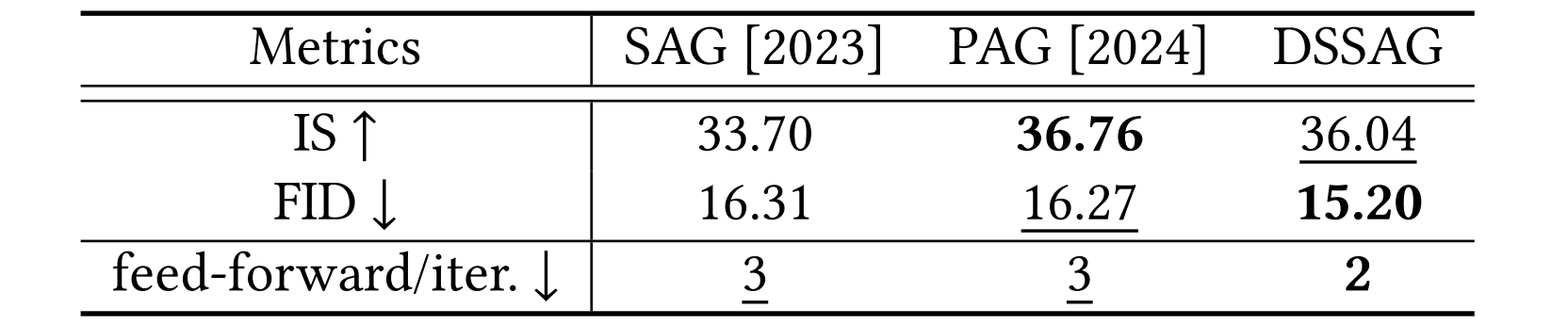
Detail-Suppression Self-Attention Guidance (DSSAG) can enhance various visual synthesis tasks, such as image and video generation. DSSAG provides additional guidance within the Classifier-Free Guidance (CFG) mechanism by degrading the predicted unconditional noise, without requiring an additional feed-forward pass. Compared to other diffusion guidance approaches, such as SAG and PAG, DSSAG achieves comparable performance while being 1.5× faster when combined with CFG. The table below presents Inception Score (IS) and Fréchet Inception Distance (FID) of diffusion guidance approaches on image synthesis task using CFG. The best and second-best scores are marked in bold and underline, respectively.


BibTeX
@inproceedings{10.1145/3721238.3730719,
author = {Han, Janghyeok and Sim, Gyujin and Kim, Geonung and Lee, Hyun-Seung and Choi, Kyuha and Han, Youngseok and Cho, Sunghyun},
title = {DC-VSR: Spatially and Temporally Consistent Video Super-Resolution with Video Diffusion Prior},
year = {2025},
isbn = {9798400715402},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3721238.3730719},
doi = {10.1145/3721238.3730719},
booktitle = {Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers},
articleno = {141},
numpages = {11},
keywords = {Video Super-Resolution, Real-World Video, Video Generative Prior},
location = {Vancouver, BC, Canada},
series = {SIGGRAPH Conference Papers '25}
}